

微信号:weixin888
对比pytorch的优化器实现及使用方法?
概述?
基本用法?
基类入参设置及支持的方法?
基类入参?
基类支持的方法?
自定义优化器?
API映射?
对比pytorch的优化器实现及使用方法?
概述?
优化器在模型训练过程中,用于计算和更新网络参数,本文对比MindSpore和pytorch的在这一部分的实现方式差异,分别从基本用法,基类入参设置及支持的方法,自定义优化器,API映射四部分展开。?
?
基本用法?
MindSpore:MindSpore除了封装了Model高阶API来方便用户定义和训练网络,在定义Model时指定优化器;也提供了TrainOneStepCell接口,通过传入优化器和一个WithLossCell的实例,自定义训练网络;在pynative模式下,也可以实现单步执行优化器。?
?
代码样例如下,首先定义网络、损失函数和优化器,再分别大致介绍优化器的三种使用场景。?
复制
复制
复制
复制
pytorch:torch为Tensor建立了grad属性和backward方法,tensor.grad是通过tensor.backward方法(本质是torch.autograd.backward)计算的,且在计算中进行梯度值累加,因此一般在调用tensor.backward方法前,需要手动将grad属性清零。?
?
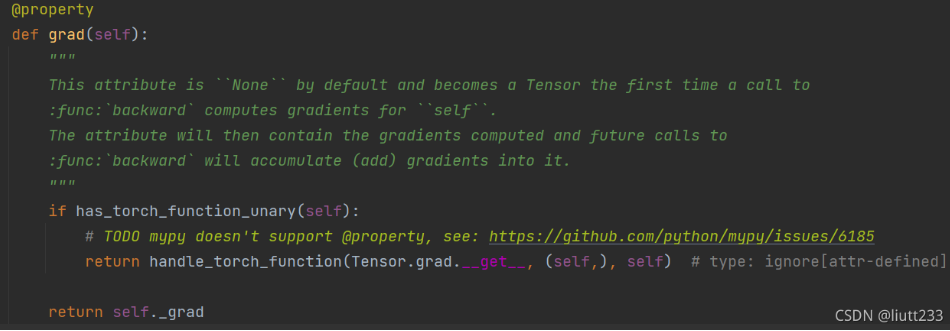
在下面的代码中,初始化了一个优化器实例,每次循环调用zero_grad清零梯度,backward更新梯度,step更新网络参数,返回损失。?
复制
基类入参设置及支持的方法?
基类入参?
MindSpore?
复制
pytorch:?
复制
1. 网络中需要被训练的参数
MindSpore和pytorch的优化器都需要传入网络中需要被训练的参数,且参数的设置同时都支持默认接口和用户自定义设置两种方式。?
?
默认接口:?
MindSpore的parameter包含了网络中所有的参数,通过require_grad属性来区分是否需要训练和优化。trainable_params方法返回一个filter的list,筛选了网络中require_grad属性为True的parameter。?
复制
pytorch的state包含了网络中所有的参数,其中需要被优化的是parameter,不需要优化的是buffer(例如:BatchNorm中的running_mean和running_var )。parameters方法返回需要被优化参数的generator。?
复制
用户自定义:?
MindSpore和pytorch都支持用户自定义传入需要优化的参数,例如,对非卷积参数进行训练和优化。代码样例如下:?
复制
复制
2. 学习率?
使用固定学习率时,用法相同,传入固定值即可;使用动态学习率时,MindSpore和pytorch都支持动态学习率调整策略,实现方式略有不同。?
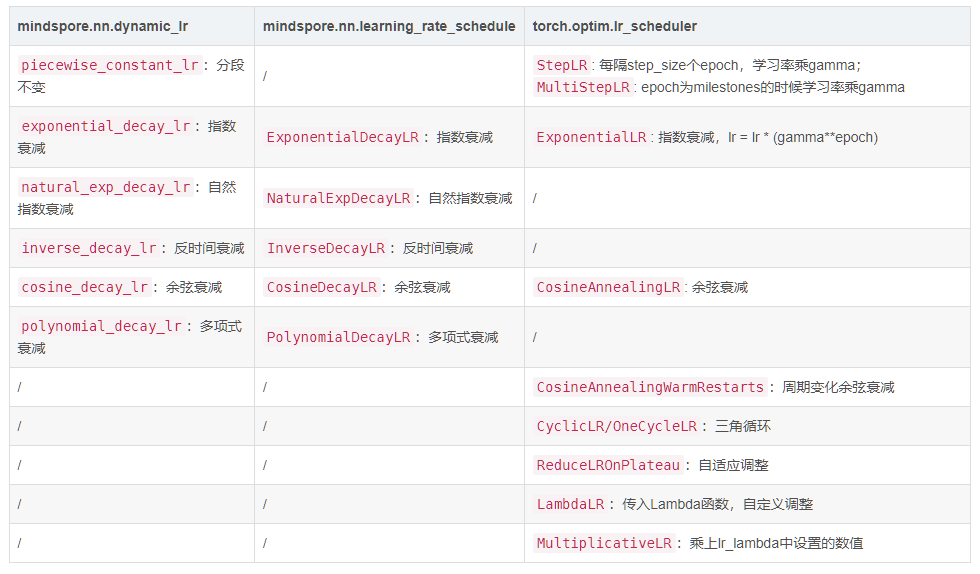
MindSpore:动态学习率有两种实现方式,预生成列表mindspore.nn.dynamic_lr和计算图格式mindspore.nn.learning_rate_schedule,且动态学习率实例作为优化器的参数输入。?
?
pytorch:优化器作为lr_scheduler的输入,调用step方法对学习率进行更新。?
复制
复制
调整策略映射表?
?
3. weight decay?
用法相同。一般情况下,weight_decay取值范围为[0, 1),实现对(BatchNorm以外的)参数使用权重衰减的策略,以避免模型过拟合问题;weight_decay的默认值为0.0,此时不使用权重衰减策略。?
?
4. 参数分组?
MindSpore和pytorch都支持参数分组且使用方法相似,在使用时都是给优化器传入一个字典的列表,每个字典对应一个参数组,其中key为参数名,value为对应的设置值。不同点是,MindSpore只支持对“lr”,“weight_decay”,“grad_centralizaiton”实现分组,pytoch支持对所有参数进行分组。此外,pytorch还支持add_param_group方法,对参数组进行添加和管理。?
?
同时,在分组获取学习率时,pytorch通过?
注:MindSpore和pytorch各自有部分优化器不支持参数分组,请参考具体优化器的实现。?
?
MindSpore参数分组用法请参考编程指南;pytorch参数分组用法参考下述样例:?
复制
5.混合精度?
Mindspore中的混合精度场景下,如果使用FixedLossScaleManager进行溢出检测,且drop_overflow_update为False时,优化器需设置loss_scale的值,且loss_scale值与FixedLossScaleManager的相同,详细使用方法可以参考优化器的混合精度配置。torch的混合精度设置不作为优化器入参。?
?
基类支持的方法?
1. 获取LR?
torch.optim.lr_scheduler.get_last_lr():根据参数组返回对应的最新学习率数值的列表。?
mindspore中没有直接可以按照组别获取对应学习率的功能,但提供了以下方法辅助使用:?
mindspore.nn.optimizer.get_lr():获取当前step的学习率,可以在自定义优化器时,在construct方法中使用。?
mindspore.nn.optimizer.get_lr_parameter(params):获取指定参数组的参数学习率列表,如果是固定学习率,返回一个标量Parameter的列表;如果是计算图格式的动态学习率,返回一个Cell的列表;如果是列表格式的动态学习率,返回shape为(n,)的Parameter的列表(其中n是动态学习率列表的长度)。?
?
2. 获取优化器的状态?
torch.optimizer.param_groups:获取优化器相关配置参数的状态,返回数据格式为字典的列表,key为参数名,value为参数值。以SGD为例,字典的key为key为’params’, ‘lr’, ‘momentum’, ‘dampening’, ‘weight_decay’, 'nesterov’等。?
torch.optimizer.state_dict():获取optimizer的状态,返回一个key为“state”,“param_groups”,value为对应数值的字典。?
MindSpore暂无对应功能。?
?
自定义优化器?
Mindspore和pytorch都支持用户基于python基本语法及相关算子自定义优化器。在torch中,通过重写__init__和step方法,用户可以根据需求自定义优化器,具体用法可以参考WRITING YOUR OWN OPTIMIZERS IN PYTORCH。MindSpore也支持类似用法,以Momentum为例:?
复制
API映射?
Mindspore和pytorch的API对应关系和差异可以参考API映射,其余暂时没有对应关系的接口目前情况如下:?
复制


















