

微信号:weixin888
机器学习中,有很多优化方法来寻找模型的最优解。
梯度下降法是最基本的一类优化器,目前主要分为三种梯度下降法:
假设训练样本总数为 ,每次输入和输出的样本分别为
,模型参数为
,损失函数为
,每输入一个样本
损失函数关于
的梯度为
,学习率为
我们以线性回归为例:
损失函数:
样本 损失函数关于
的梯度:
则使用梯度下降法更新参数为:
其中, 表示
时刻的模型参数。
从表达式来看,模型参数的更新调整,与损失函数关于模型参数的梯度有关,即沿着梯度的方向不断减小模型参数,从而最小化损失函数。
基本策略可以理解为”在有限视距内寻找最快路径下山“,因此每走一步,参考当前位置最陡的方向(即梯度)进而迈出下一步。可以形象的表示为:

SGD主要有两个缺点:

假设批量训练样本总数为 ,每次输入和输出的样本分别为
,模型参数为
,损失函数为
,每输入一个样本
损失函数关于
的梯度为
,学习率为
其中, 表示
时刻的模型参数。
模型参数的调整更新与全部输入样本(批量训练样本)的损失函数的和(即批量/全局误差)有关。即每次权值调整发生在批量样本输入之后,而不是每输入一个样本就更新一次模型参数。这样就会大大加快训练速度。
基本策略可以理解为,在下山之前掌握了附近的地势情况,选择总体平均梯度最小的方向下山。
对比批量梯度下降法,假设从一批训练样本 中随机选取一个样本
。模型参数为
,损失函数为
,梯度为
,学习率为
,则使用随机梯度下降法更新参数表达式为:
其中, 表示随机选择的一个梯度方向,
表示
时刻的模型参数。
,这里虽然引入了随机性和噪声,但期望仍然等于正确的梯度下降。
我们可以从图中看出SGD迭代的次数较多,在解空间的搜索过程看起来很盲目。但是大体上是往着最优值方向移动。
优点:
1. 虽然SGD需要走很多步,但是对梯度的要求很低(计算梯度快)。而对于引入噪声,大量的理论和实践工作证明,只要噪声不是特别大,SGD都能很好地收敛。
2. 应用大型数据集时,训练速度很快。比如每次从百万数据样本中,取几百个数据点,算一个SGD梯度,更新一下模型参数。相比于标准梯度下降法的遍历全部样本,每输入一个样本更新一次参数,要快得多。
缺点:
1. SGD在随机选择梯度的同时会引入噪声,使得权值更新的方向不一定正确。
2. 此外,SGD也没能单独克服局部最优解的问题。
我们从上面两种梯度下降法可以看出,其各自均有优缺点,那么能不能在两种方法的性能之间取得一个折衷呢?即,算法的训练过程比较快,而且也要保证最终参数训练的准确率,而这正是小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD)的初衷。
对于深度学习模型而言,人们所说的“随机梯度下降, SGD”,其实就是基于小批量(mini-batch)的随机梯度下降。
与批梯度下降最大的区别就在于,我们这里更新参数的时候,并没有将所有训练样本考虑进去,然后求和除以总数,而是我自己编程实现任取一个样本点,然后利用这个样本点进行更新!这就是最大的区别!
#coding=utf-8
import numpy as np
import random
#下面实现的是批量梯度下降法
def batchGradientDescent(x, y, theta, alpha, m, maxIterations):
xTrains = x.transpose() #得到它的转置
for i in range(0, maxIterations):
hypothesis = np.dot(x, theta)
loss = hypothesis - y
# print loss
gradient = np.dot(xTrains, loss) / m #对所有的样本进行求和,然后除以样本数
theta = theta - alpha * gradient
return theta
#下面实现的是随机梯度下降法
def StochasticGradientDescent(x, y, theta, alpha, m, maxIterations):
data = []
for i in range(10):
data.append(i)
xTrains = x.transpose() #变成3*10,没一列代表一个训练样本
# 这里随机挑选一个进行更新点进行即可(不用像上面一样全部考虑)
for i in range(0,maxIterations):
hypothesis = np.dot(x, theta)
loss = hypothesis - y #注意这里有10个样本的,我下面随机抽取一个进行更新即可
index = random.sample(data,1) #任意选取一个样本点,得到它的下标,便于下面找到xTrains的对应列
index1 = index[0] #因为回来的时候是list,我要取出变成int,更好解释
gradient = loss[index1]*x[index1] #只取这一个点进行更新计算
theta = theta - alpha * gradient.T
return theta
def predict(x, theta):
m, n = np.shape(x)
xTest = np.ones((m, n+1)) #在这个例子中,是第三列放1
xTest[:, :-1] = x #前俩列与x相同
res = np.dot(xTest, theta) #预测这个结果
return res
trainData = np.array([[1.1,1.5,1],[1.3,1.9,1],[1.5,2.3,1],[1.7,2.7,1],[1.9,3.1,1],[2.1,3.5,1],[2.3,3.9,1],[2.5,4.3,1],[2.7,4.7,1],[2.9,5.1,1]])
trainLabel = np.array([2.5,3.2,3.9,4.6,5.3,6,6.7,7.4,8.1,8.8])
m, n = np.shape(trainData)
theta = np.ones(n)
alpha = 0.1
maxIteration = 5000
#下面返回的theta就是学到的theta
theta = batchGradientDescent(trainData, trainLabel, theta, alpha, m, maxIteration)
print "theta=",theta
x = np.array([[3.1, 5.5], [3.3, 5.9], [3.5, 6.3], [3.7, 6.7], [3.9, 7.1]])
print predict(x, theta)
theta = StochasticGradientDescent(trainData, trainLabel, theta, alpha, m, maxIteration)
print "theta=",theta
x = np.array([[3.1, 5.5], [3.3, 5.9], [3.5, 6.3], [3.7, 6.7], [3.9, 7.1]])
print predict(x, theta)
#yes,is the code动量优化方法是在梯度下降法的基础上进行的改变,具有加速梯度下降的作用。
可以想象成一个很扁的漏斗,这样在竖直方向上,梯度就非常大,在水平方向上,梯度就相对较小,所以我们在设置学习率的时候就不能设置太大,为了防止竖直方向上参数更新太过了,这样一个较小的学习率又导致了水平方向上参数在更新的时候太过于缓慢,所以就导致最终收敛起来非常慢。
momentum算法思想:参数更新时在一定程度上保留之前更新的方向,同时又利用当前batch的梯度微调最终的更新方向,简言之就是通过积累之前的动量来加速当前的梯度。
下面一张图可以很直观地表达Momentum算法的思想。举个简单例子,假设上次更新时梯度是往前走的,这次更新的梯度算出来是往左走,这变化太剧烈了,所以我们来做个折中,往左前方走。感觉上,像是上次更新还带有一定的惯性。
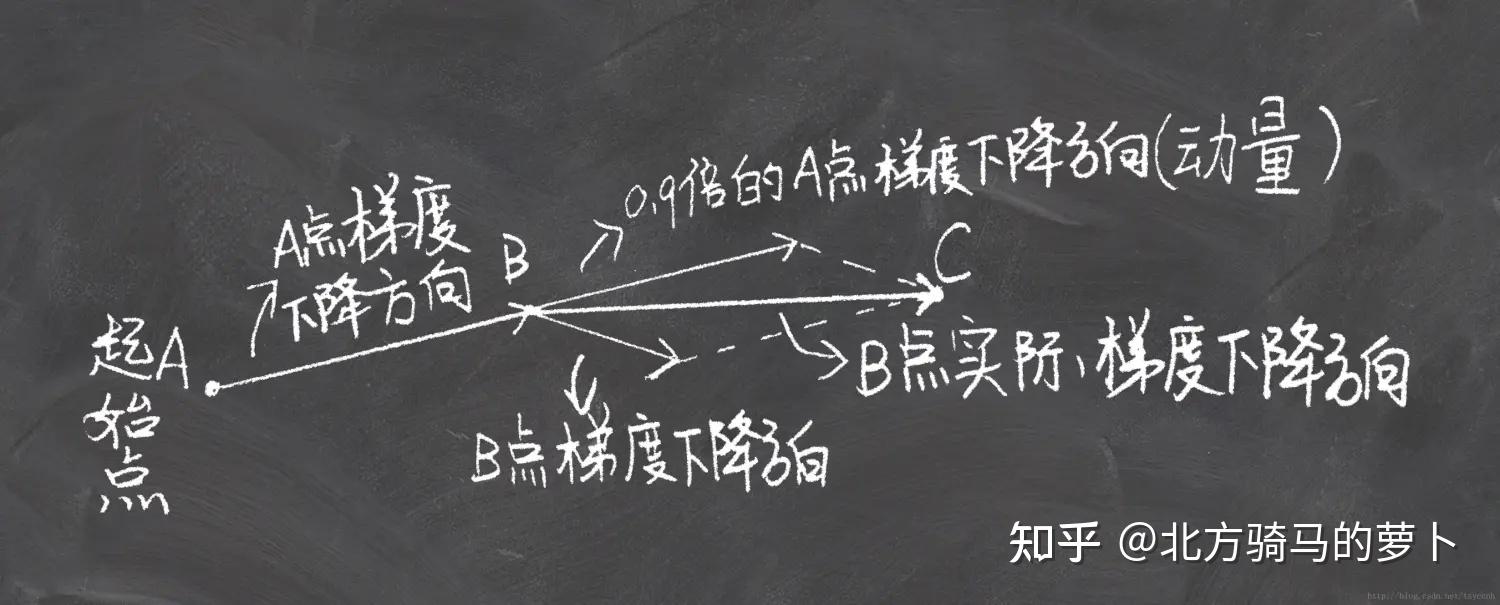
先给出一些符号规定,? 为损失函数,
参数,
为学习率,
表示走了前
步所积累的动量和,
是动量因子(上图中的0.9倍就是动量因子),一般取值为0.9(表示最大速度10倍于SGD)。
动量主要解决SGD的两个问题:
理解策略为:由于当前权值的改变会受到上一次权值改变的影响,类似于小球向下滚动的时候带上了惯性。这样可以加快小球向下滚动的速度。
一般而言,在迭代初期,梯度方向都比较一致,动量法会起到加速作用,可以更快地到达最优点。在迭代后期,梯度方向会取决不一致,在收敛值附近震荡,动量法会起到减速作用,增加稳定性。从某种角度来说,当前梯度叠加上部分的上次梯度,一定程度上可以近似看作二阶梯度。
——参考:邱锡鹏:《神经网络与深度学习》
机器学习 | 优化——动量优化法(更新方向优化)
牛顿加速梯度(NAG, Nesterov accelerated gradient)算法,是Momentum动量算法的变种。更新模型参数表达式如下:
: 其中
就表示,先按照
的方向先走一步,走完再求梯度
其中, ? 为损失函数,
为参数,
为学习率,
表示走了前
步所积累的动量和,
表示动力的大小。
表示损失函数关于
的梯度。
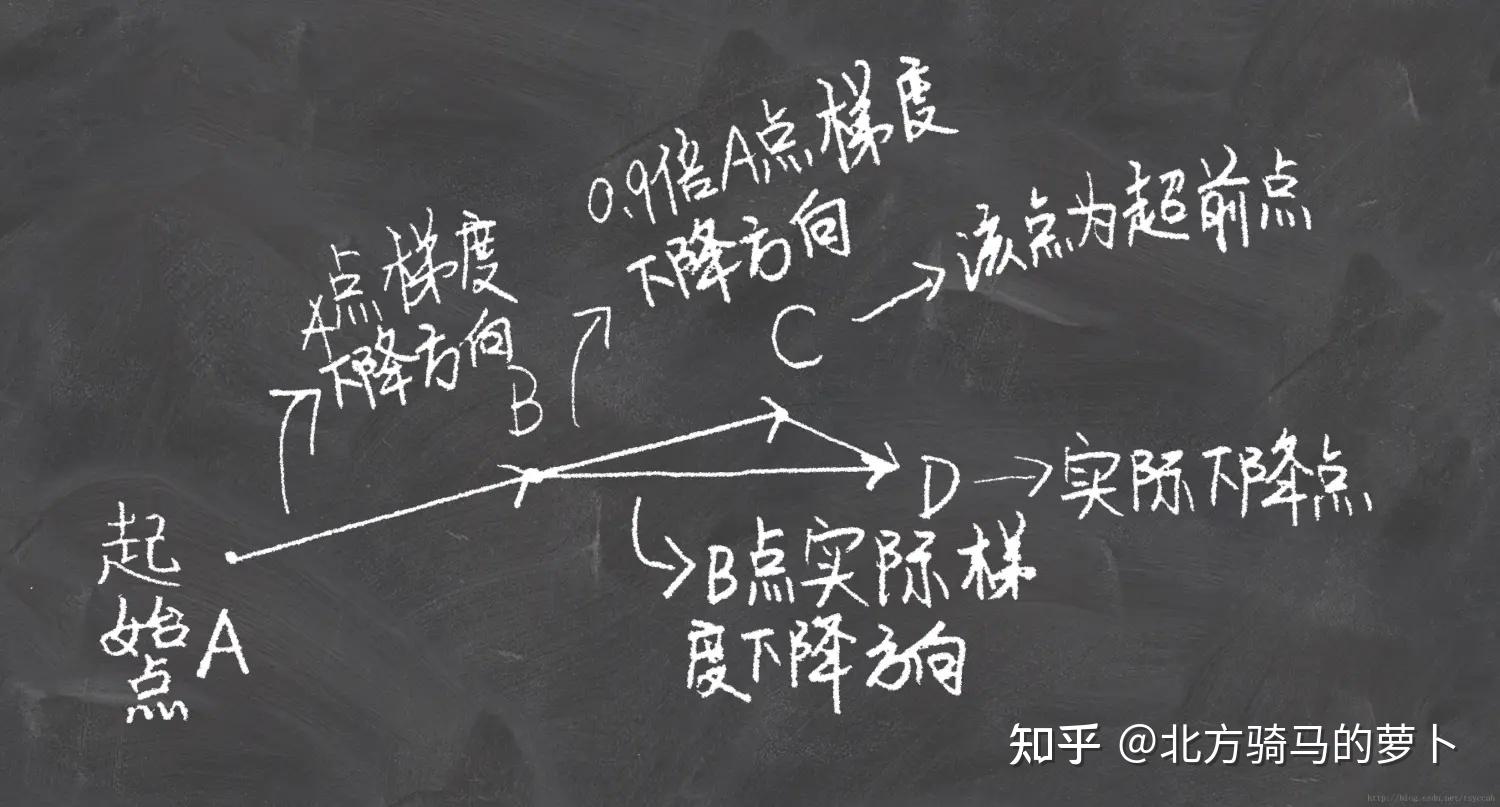
Nesterov动量梯度的计算在模型参数施加当前速度之后,因此可以理解为往标准动量中添加了一个校正因子。
以下是看到的一些解释:
在Momentun中小球会盲目地跟从下坡的梯度,容易发生错误。所以需要一个更聪明的小球,能提前知道它要去哪里,还要知道走到坡底的时候速度慢下来而不是又冲上另一个坡。计算可以表示小球下一个位置大概在哪里。从而可以提前知道下一个位置的梯度,然后使用到当前位置来更新参数。
经过变换之后的等效形式中,NAG算法相对于Momentum多了一个本次梯度相对上次梯度的变化量,这个变化量本质上是对目标函数二阶导的近似。通过这个二阶导的近似能提前知道它要去哪里,还要知道走到坡底的时候速度慢下来而不是又冲上另一个坡。
在凸批量梯度的情况下,Nesterov动量将额外误差收敛率从(
步后)改进到
。然而,在随机梯度情况下,Nesterov动量对收敛率的作用却不是很大。
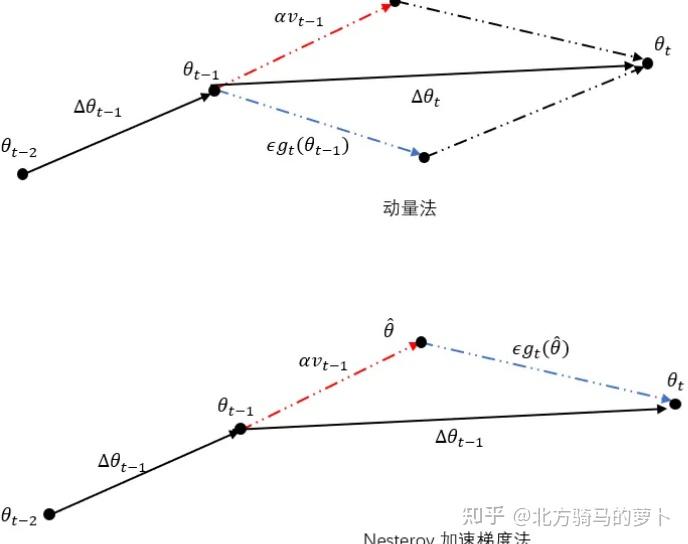
它是利用当前位置处先前的梯度值先做一个参数更新,然后在更新后的位置再求梯度,将此部分梯度然后跟之前累积下来的梯度值矢量相加,简单的说就是先根据之前累积的梯度方向模拟下一步参数更新后的值,然后将模拟后的位置处梯度替换动量方法中的当前位置梯度。为什么解决了之前说的那个问题呢?因为现在有一个预测后一步位置梯度的步骤,所以当在山谷附近时,预测到会跨过山谷时,该项梯度就会对之前梯度有个修正,相当于阻止了其跨度太大。下面这张图对其有个形象描述,其中蓝色线表示动量方法,蓝色短线表示当前位置梯度更新,蓝色长线表示之前累积的梯度;第一个红色线表示用NAG算法预测下一步位置的梯度更新,第一条棕色线表示先前累积的梯度,其矢量相加结果(绿色线)就是参数更新的方向。
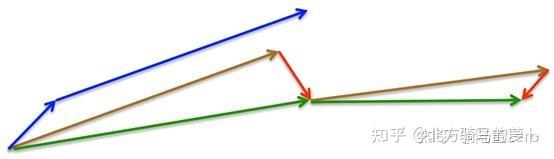
momentum与Nesterov的区别如下图所示:
==========================自适应学习率优化算法==================================
自适应学习率优化算法针对于机器学习模型的学习率,传统的优化算法要么将学习率设置为常数要么根据训练次数调节学习率。极大忽视了学习率其他变化的可能性。然而,学习率对模型的性能有着显著的影响,因此需要采取一些策略来想办法更新学习率,从而提高训练速度。
目前的自适应学习率优化算法主要有:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法。
AdaGrad算法,独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平均值总和的平方根。具有损失函数最大梯度的参数相应地有个快速下降的学习率,而具有小梯度的参数在学习率上有相对较小的下降。(有点绕,不太懂)
基础的批量梯度下降法还有改进的空间吗? 有的,这就是后来的Adagrad算法。
Adagrad算法是一种梯度下降法,它是对批量梯度下降法的改进,但并不是对动量法的改进。Adagrad算法的目的是在解决优化问题时自动调整学习率,以便能够更快地收敛。
在优化问题中,我们通常需要找到使目标函数最小的参数值。批量梯度下降法是一种求解此类问题的方法,它在每次迭代时使用整个数据集来计算梯度。然而,批量梯度下降法的收敛速度可能较慢,因为它需要较多的计算。Adagrad算法在每次迭代中,会根据之前的梯度信息自动调整每个参数的学习率。
具体来说,使用如下公式:
: 第i个参数
:学习率
:第t次迭代中参数i的梯度
: 参数i在每次迭代中的梯度平方和,开根号
Adagrad算法会在每次迭代中计算每个参数的梯度平方和,并使用这些平方和来调整学习率。这样,Adagrad算法就可以使用较小的学习率来解决那些更难优化的参数,而使用较大的学习率来解决更容易优化的参数。
例如,在文本处理中训练词嵌入模型的参数时,有的词或词组频繁出现,有的词或词组则极少出现。数据的稀疏性导致相应参数的梯度的稀疏性,不频繁出现的词或词组的参数的梯度在大多数情况下为零,从而这些参数被更新的频率很低。
在应用中,我们希望更新频率低的参数可以拥有较大的更新步幅,而更新频率高的参数的步幅可以减小。
AdaGrad方法采用“历史梯度平方和”来衡量不同参数的梯度的稀疏性,取值越小表明越稀疏
跟着下面的思路理解一下:
在梯度下降算法中:
在Adagrad算法中,(不频繁出现的词或词组的参数的梯度在大多数情况下为零,这意味着,不频繁出现的词对应的
)也就越大)(如果某个参数更新频繁,那么它的真实学习率将变小,而更新不频繁的参数,它的真实学习率就相对较大。)
从而Adagrad算法就实现了:对于比较多的类别数据给予越来越小的学习率,而对于比较少的类别数据,会给予较大的学习率。因此Adagrad适用于数据稀疏或者分布不平衡的数据集。
优势:
Adagrad 的主要优势在于不需要人为的调节学习率,它可以自动调节;
缺点:
缺点在于,随着迭代次数增多,学习率会越来越小,最终会趋近于0。对于训练深度神经网络模型而言,从训练开始时累积平方梯度值会越来越大,会导致学习率过早和过量的减少,从而导致迭代后期收敛及其缓慢。
Adagrad 算法对于不同的参数调整学习率的方式是固定的,不能根据不同的任务自动调整。这意味着在某些情况下,Adagrad 算法可能不能很好地处理模型的学习问题。
Adagrad算法优化了学习率的调整,但仍然存在一些问题。随着迭代次数增多,学习率会越来越小,最终会趋近于0。为此,科学家们提出了RMSProp 算法。
RMSProp 算法通过自动调整每个参数的学习率来解决这个问题。它在每次迭代中维护一个指数加权平均值,用于调整每个参数的学习率。如果某个参数的梯度较大,则RMSProp算法会自动减小它的学习率;如果梯度较小,则会增加学习率。这样可以使得模型的收敛速度更快。
波动幅度大的梯度具有较大的方差, RMSProp 算法将原来的梯度除以方差的平方根来更新参数,同样可以达到纵向上相互抵消,横向上累积的目标。RMSProp 算法可以由如下公式化:
: (加权平均)
表示前
次的梯度平方的均值,
是动量因子一般取值为0.9
:
表示全局初始学习率。
是一个取值很小的数(一般为1e-8)避免分母为0
优点方面,RMSProp算法能够自动调整学习率,使得模型的收敛速度更快。它可以避免学习率过大或过小的问题,能够更好地解决学习率调整问题。
RMSProp主要思想:使用指数加权移动平均的方法计算累积梯度,以丢弃遥远的梯度历史信息(让距离当前越远的梯度的缩减学习率的权重越小)。
RMSProp算法不是像AdaGrad算法那样暴力直接的累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少。
============对比Adagrad与RMSProp===========
RMSProp增加了一个衰减系数来控制历史信息的获取多少
举个例子说明Adagrad和RMSProp相对于梯度下降法的优势:

从上图可以看出在b方向上的梯度g要大于在w方向上的梯度。累积平方梯度 和
作为分母,分母越大(梯度大-b)更新越小,分母越小(梯度小-w)更新越大。那么后面的更新则会像下面绿色线更新一样,明显就会好于蓝色更新曲线。
AdaDelta算法的基本思想是避免使用手动调整学习率的方法来控制训练过程,而是自动调整学习率,使得训练过程更加顺畅。(AdaGrad算法和RMSProp算法都需要指定全局学习率 )
AdaDelta算法策略可以表示为:
AdaDelta算法: ,从表达式可以看出,AdaDelta不需要设置一个默认的全局学习率。
它的名称来源于适应性矩估计(adaptive moment estimation)。
Adam优化算法基本上就是将Momentum(momentum,Nesterov)和RMSprop(Adagrad,AdaDelta)结合在一起。
一阶矩: 一阶矩就是期望值,换句话说就是平均数.
二阶矩:二阶(非中心)矩就是对变量的平方求期望,二阶中心矩就是对随机变量与均值(期望)的差的平方求期望。
原点矩: 令为任何实数,
为随机变量,则期望值
叫做随机变量
,则有
,称为k阶原点矩,记
,
。
二阶中心矩:也叫作方差,它告诉我们一个随机变量在它均值附近波动的大小,方差越大,波动性越大。方差也相当于机械运动中以重心为转轴的转动惯量。
三阶中心矩:告诉我们一个随机密度函数向左或向右偏斜的程度。
需要区分一个概念:优化算法 ≠ 损失函数
损失函数只是用来计算损失的,而优化算法(函数)是根据损失函数得到的损失值来更新参数的。
Adam算法涉及到的公式计算有如下部分:
Adam算法:
分别对上述变量做一个理解:
它们的物理意义考虑如下:
则 和
有以下几种情况:
Adam的参数配置
Adam论文建议的参数设定:
alpha=0.001、beta1=0.9、beta2=0.999 和 epsilon=10E?8。
优化算法常用tricks:
刚入门,优先考虑:SGD+Nesterov Momentum或者Adam。
选择熟悉的算法。
充分了解数据。---模型非常稀疏,则优先考虑自适应学习率算法Adam等。
根据需求选择。--快速验证,Adam,模型上线或者结果发布前,精调的SGD进行模型的极致优化。
先用小数据集实验。有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系不大。因此可以先用一个具有代表性的小数据集进行实验,测试一下最好的优化算法,并通过参数搜索来寻找最优的训练参数。
考虑不同算法的组合。先用Adam进行快速下降,而后再换到SGD进行充分的调优。切换策略可以参考本文介绍的方法。
数据集一定要充分的打散(shuffle)。这样在使用自适应学习率算法的时候,可以避免某些特征集中出现,而导致的有时学习过度、有时学习不足,使得下降方向出现偏差的问题。
训练过程中持续监控训练数据和验证数据上的目标函数值以及精度或者AUC等指标的变化情况。对训练数据的监控是要保证模型进行了充分的训练——下降方向正确,且学习率足够高;对验证数据的监控是为了避免出现过拟合。
制定一个合适的学习率衰减策略。可以使用定期衰减策略,比如每过多少个epoch就衰减一次;或者利用精度或者AUC等性能指标来监控,当测试集上的指标不变或者下跌时,就降低学习率。

下降速度:
下降轨迹:
(对比内容待补充。。。)
参考文献:
Adam Algorithm & First-order moment, Second moment
机器学习:各种优化器Optimizer的总结与比较_机器学习中各种优化器的分析与比较-CSDN博客
Lu1zero9:深度学习随笔——优化算法( SGD、BGD、MBGD、Momentum、NAG、Adagrad、RMSProp、AdaDelta、Adam、NAdam)


















